离职系列之<1/3>--平权
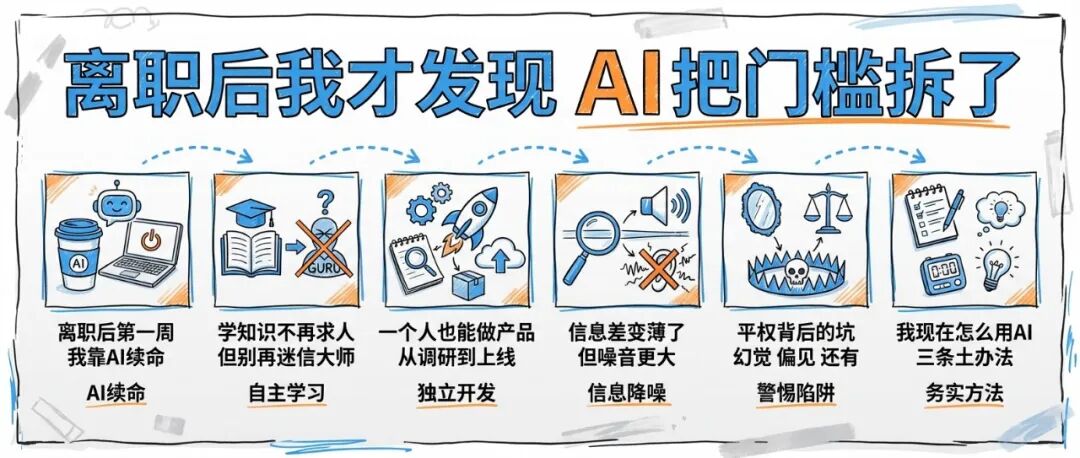
我离职那天背着电脑回家,路上还挺硬气:不干了,老子要自由。结果到家,第二天5点半就醒了,开始心虚——没工位、没同事、没人催我开会,银行卡余额也不会因为“自我实现”而自动增长。
那几天我最真实的状态是:一边焦虑,一边抱着AI聊天窗口当救生圈。不是那种“未来已来”的兴奋,更像是溺水的人突然摸到一块浮板:原来很多以前必须求人、必须组队、必须花钱的东西,现在我一个人,靠一台笔记本和网线,也能把事推进去。
后来我慢慢明白,我对AI最大的感受不是“变强”,而是三个字:门槛低了。甚至可以说,是某种平权。
01 离职后第一周 我对AI的发现!
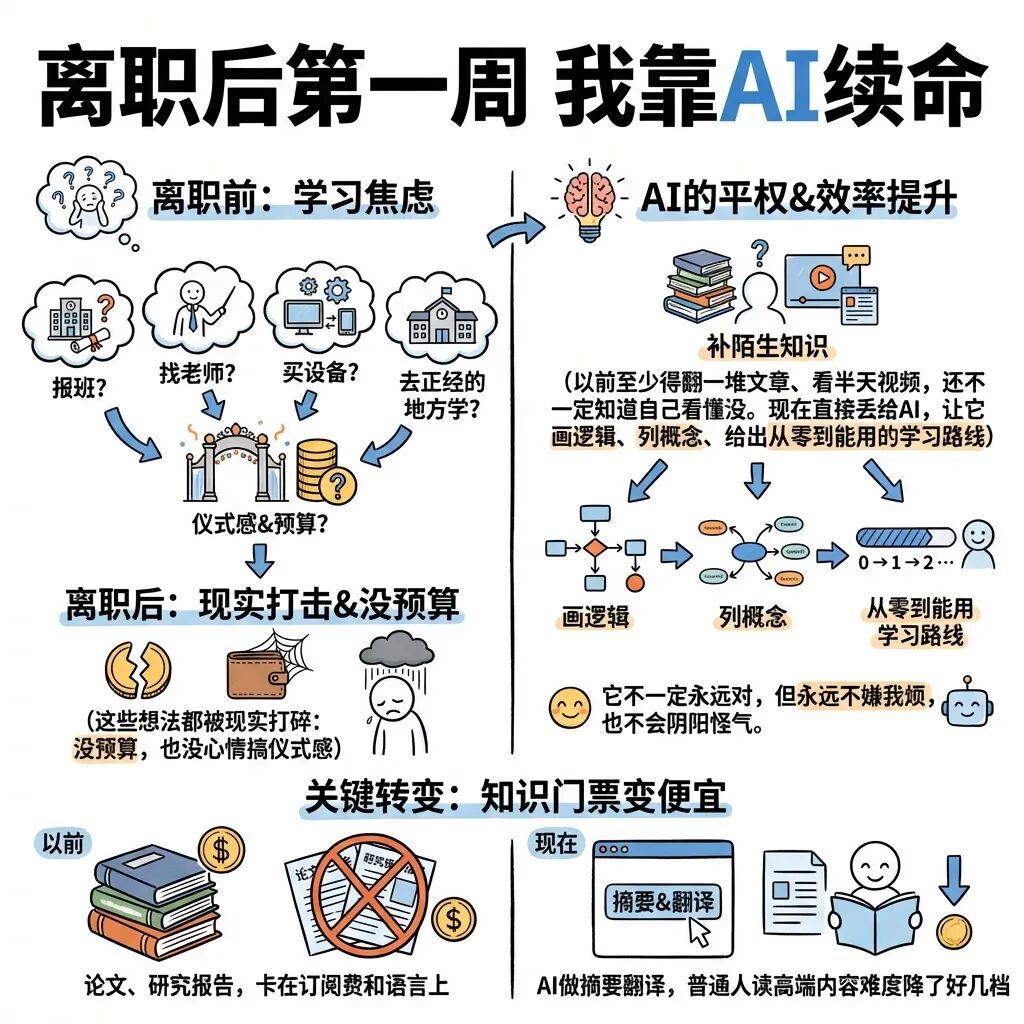
离职前我对“学习”这件事挺怂的。想学点新东西,总会先想到:要不要报班?要不要找老师?要不要买设备?要不要去个正经的地方学?
离职后这些想法都被现实打碎:我没预算,也没心情搞那些仪式感。
我第一次强烈感到AI的“平权”,是在一个很小的场景:我想快速补一块陌生领域的知识(偏业务的那种),以前我至少得翻一堆文章、看半天视频、还不一定知道自己看懂没。现在我直接把我看不懂的段落丢给AI,让它给我画逻辑、列概念、顺便给我一个“从零到能用”的学习路线。
它不一定永远对,但它永远不嫌我烦,也不会阴阳怪气“这个你都不知道”。
更关键的是,知识的“门票”也在变便宜。以前很多论文、研究报告,卡在订阅费和语言上,普通人根本不可能为了一个问题去付一套数据库的钱。现在开放获取(OA)本来就越来越普遍,再加上AI做摘要、翻译、推荐,普通人读“看似高端”的东西,难度确实降了好几档。
“超过50%的学术文章已通过开放获取等方式免费可用……AI正在加速研究传播与协作。” — Integranxt(引用UNESCO 2023趋势)[https://integranxt.com/blog/ai-and-the-future-of-open-access-publishing-revolutionizing-academic-research-and-dissemination/]
我不想把这说得太伟大,它对我就是很现实的一件事:以前我得先找到“门”,现在门就摆在我面前,还自带说明书。
02 学知识不再求人 但别再迷信大师
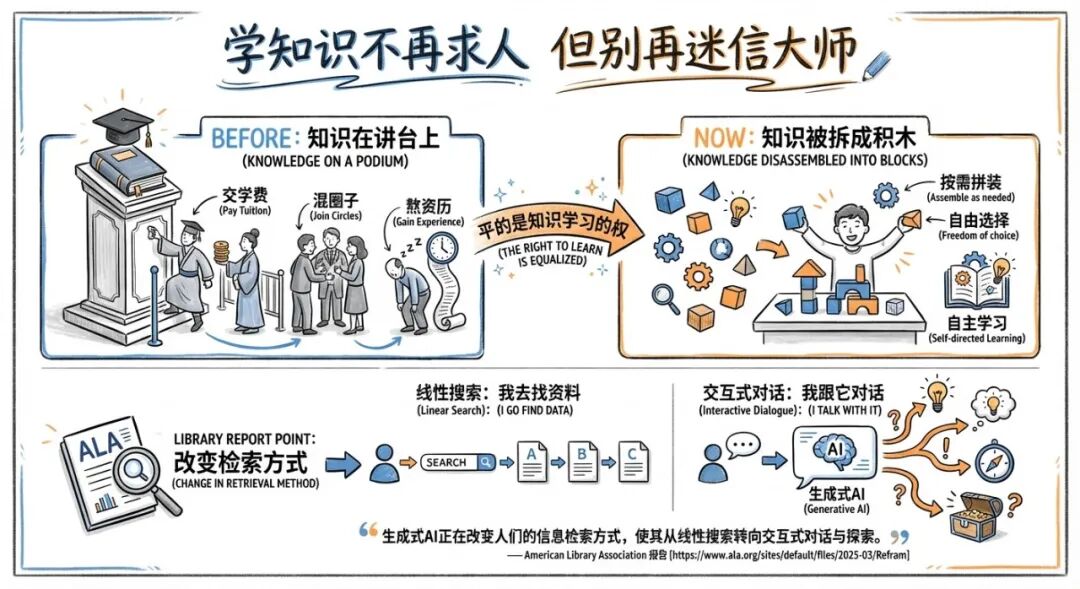
“平的是知识学习的权”这句话,我现在特别有体感:以前知识像是被摆在讲台上,你要么交学费,要么混圈子,要么熬资历。现在知识更像是被拆成了积木,你可以按自己的需求拼。
图书馆系统的人写过一份报告,里面有个点我挺喜欢:生成式AI把信息检索从“我去找资料”变成“我跟它对话”,路径不再线性,甚至会走出你没想过的岔路。
“生成式AI正在改变人们的信息检索方式,使其从线性搜索转向交互式对话与探索。” — American Library Association 报告 [https://www.ala.org/sites/default/files/2025-03/ReframingInformation-SeekingintheAgeofGenerativeAI.pdf]
但我也踩过坑:AI讲得太顺了,顺到让我以为“我懂了”。后来我去看原始资料才发现,它把两个概念揉在一起讲,听起来合理,实际是错的。那一刻我突然理解:学习的权被平了,不代表真理被平了。
还有个更扎心的事:知识的“权威结构”正在变。以前你要听老师、看教材、过考试,至少有一套筛选机制。现在你刷到什么、问到什么、AI给你什么,你就学什么,容易变成“需求驱动的知识”:我想要一个结论,它就给我一个结论。
这在效率上很爽,在长期上也可能把人带歪。
“AI与大数据正在压缩‘数据—信息—知识—智慧(DIKW)’的底层环节,催生以需求为导向的知识路径;但也可能出现被‘流行度’合法化的污染知识。” — Journal of Futures Studies Digital(JFS Digital)[https://jfsdigital.org/2025-2/vol-30-no-1-september-2025/on-the-crisis-and-democratization-of-knowledge-the-sociopolitical-impact-of-ai-and-knowledge-hierarchy/]
所以我现在对“知识平权”的态度是:它确实把门槛拆了,但也把“自证其明”的责任扔回给你。你得学会不迷信,尤其别迷信那种输出特别自信、句子特别顺的AI。
03 一个人也能做产品 从调研到上线
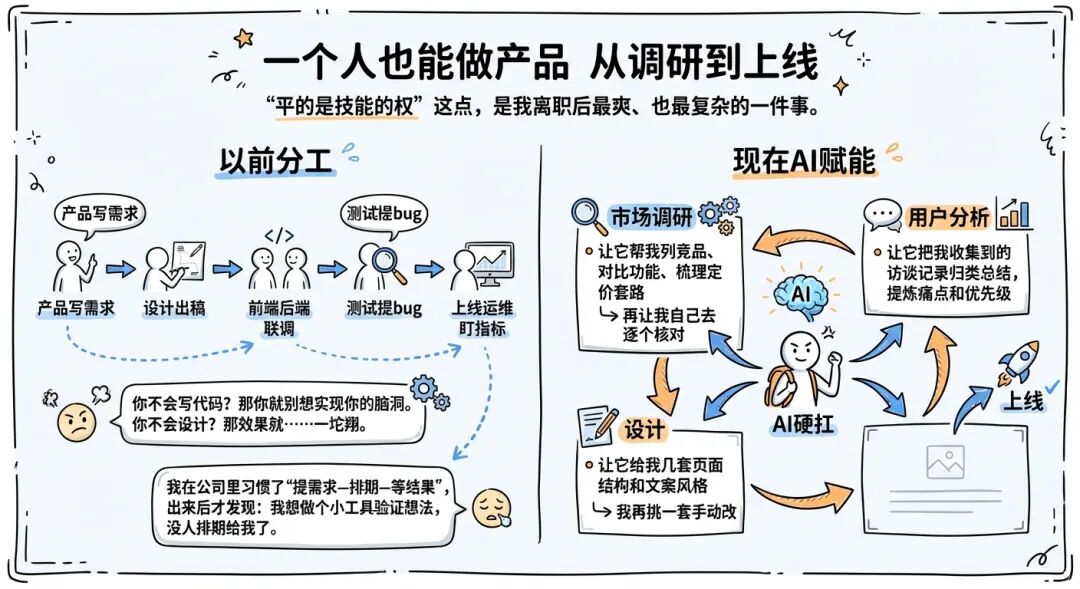
“平的是技能的权”这点,是我离职后最爽、也最复杂的一件事。
以前做事很讲究分工:产品写需求,设计出稿,前端后端联调,测试提bug,上线运维盯指标。你不会写代码?那你就别想实现你的脑洞。你不会设计?那效果就……一坨翔。
我在公司里习惯了“提需求—排期—等结果”,出来后才发现:我想做个小工具验证想法,没人排期给我了。
于是我开始用AI硬扛:
市场调研:让它帮我列竞品、对比功能、梳理定价套路,再让我自己去逐个核对;
用户分析:让它把我收集到的访谈记录归类总结,提炼痛点和优先级;
设计:让它给我几套页面结构和文案风格,我再挑一套手动改;
开发:我不会的部分让它写demo,我负责把它拼起来跑通;
测试:让它帮我列测试用例和边界条件;
部署:照着它给的脚本一步步上云。
这套流程下来,我最大的感受不是“我变成了全栈”,而是:以前需要一个小团队才能推进的事,现在一个人也能摸到60分,甚至某些环节能冲到80分。
技能的门槛真的被削平了。
“生成式AI正在降低专业门槛,使个人能够完成过去依赖团队的研究与创作流程(如文献综述、创意生成等),但仍需人类监督与方法论约束。” — Cornell Research & Innovation [https://www.research-and-innovation.cornell.edu/generative-ai-in-academic-research/]
但我也得泼冷水:AI让“能做”变容易了,但“做得好”依然很难。尤其是产品这事儿,你写得出代码,不代表有人用;你做得出页面,不代表能留存。AI可以把你从0推到1,但从1到10,很多时候得靠你自己挨打。
我现在反而更尊重那些能把“需求—方案—取舍—落地—复盘”做得扎实的人。AI像是一把更强的工具,但它不替你承担取舍的代价。
04 信息差变薄了 但噪音更大
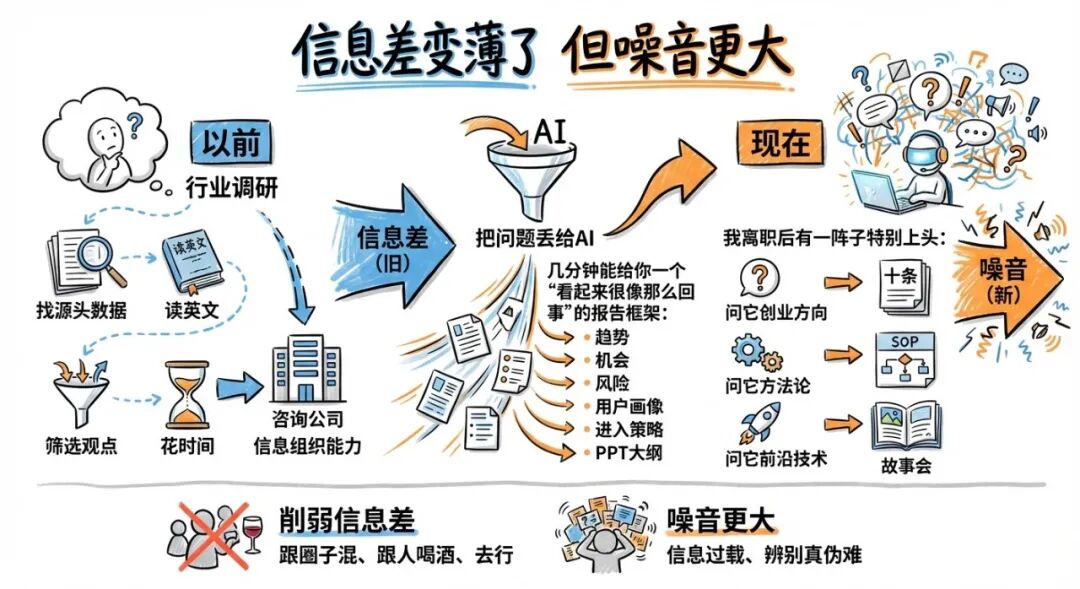
第三个“平权”我觉得最猛:信息差的权。
以前想写一份像样的行业调研,你得会找源头数据、会读英文、会筛选观点,还得花时间。很多咨询公司卖的,本质上就是“信息组织能力”。
现在呢?你把问题丢给AI,它几分钟能给你一个“看起来很像那么回事”的报告框架:趋势、机会、风险、用户画像、进入策略……甚至连PPT大纲都给你排好。
我离职后有一阵子特别上头:每天用AI刷“今天有什么新东西”,感觉自己像突然进了情报系统。你问它创业方向,它能给你十条;你问它方法论,它能给你SOP;你问它前沿技术,它能把一堆术语解释得像故事会。
这确实在削弱信息差:以前你得跟圈子混、跟人喝酒、去行业会议蹭,现在你在家穿拖鞋也能把基本盘摸清。
“55%的美国人会定期使用AI工具,但有44%的人认为自己没有使用过(实际可能已在无感使用)。” — National University AI统计汇总 [https://www.nu.edu/blog/ai-statistics-trends/]
但信息差变薄的同时,噪音也更大了。因为“产出信息”太容易了:一篇看似专业的文章、一个像模像样的数据图、一个剪辑得很燃的视频,很可能都是拼接、改写、甚至编出来的。
更麻烦的是,你很难第一眼看出它到底靠不靠谱。你以为自己站在信息高地,其实可能站在垃圾堆上。
我现在对“信息差平权”的态度是:它把获取变便宜了,但把验证变昂贵了。你省下的时间,迟早要花在“核对”和“求证”上。
05 平权背后的坑 幻觉 偏见 还有大厂垄断
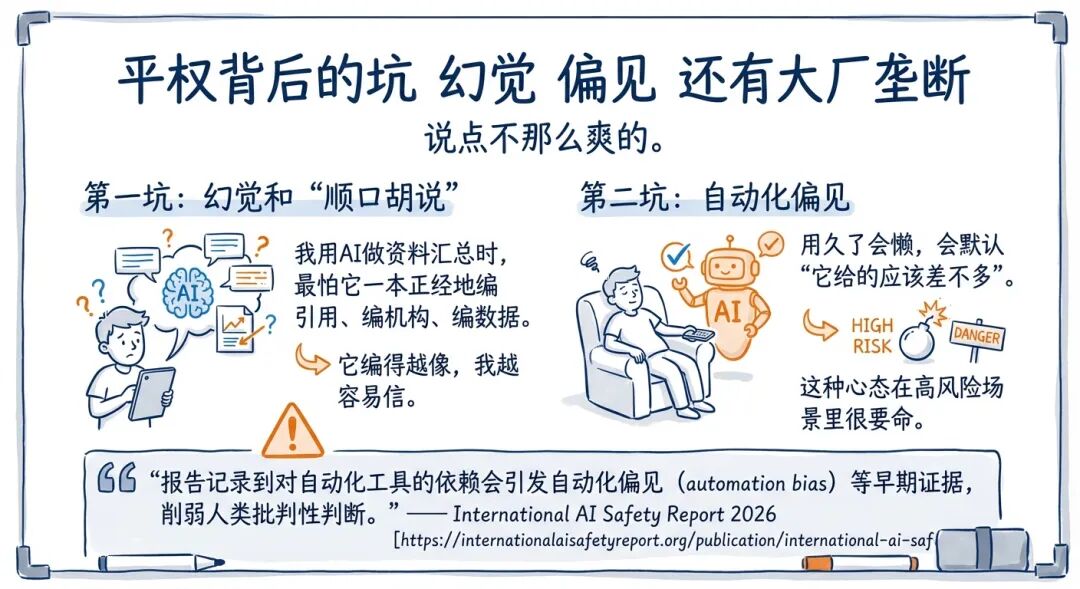
说点不那么爽的。
第一坑:幻觉和“顺口胡说”。我用AI做资料汇总时,最怕它一本正经地编引用、编机构、编数据。它编得越像,我越容易信。
第二坑:自动化偏见。用久了会懒,会默认“它给的应该差不多”。这种心态在高风险场景里很要命。
“报告记录到对自动化工具的依赖会引发自动化偏见(automation bias)等早期证据,削弱人类批判性判断。” — International AI Safety Report 2026 [https://internationalaisafetyreport.org/publication/international-ai-safety-report-2026]
第三坑更现实:所谓“平权”,可能只是“入口平了”,但权力未必平。底座模型、算力、数据、分发渠道,很多还是集中在少数公司手里。你用得很爽,但你也被它的规则牵着走:它能答什么、不能答什么;它默认推荐什么;它把哪些内容排在前面。
如果哪天接口涨价、政策变化、模型收紧,你的“平权”可能就断供了。
“一些专家对2026年的‘AI民主化’叙事持怀疑态度,认为权力将进一步集中于少数公司,且需要更强的独立监督。” — Tech Policy Press(关于2026政策风险的专家预测)[https://techpolicy.press/expert-predictions-on-whats-at-stake-in-ai-policy-in-2026]
还有个长期风险:信任被磨损。深度伪造、批量洗稿、AI生成评论带节奏……当你越来越难判断“这是真的吗”,人会变得更极端:要么什么都信,要么什么都不信。
知识平权如果最后变成“谁更会造假谁更有流量”,那就挺讽刺的。
“关于AI生成内容(如深度伪造)可能侵蚀社会信任的担忧,在2026相关讨论中被反复提及,并影响新闻、司法与公共生活。” — UC Berkeley AI专家关注点汇总 [https://vcresearch.berkeley.edu/news/11-things-uc-berkeley-ai-experts-are-watching-2026]
所以我现在的结论比较别扭:AI确实在“平权”,但它也在制造新的不平等——比如“会提问的人”和“只会复制粘贴的人”之间的差距;比如“能做验证的人”和“只看结论的人”之间的差距;再比如“掌握底层资源的人”和“只能用API的人”之间的差距。
06 我现在怎么用AI 三条土办法
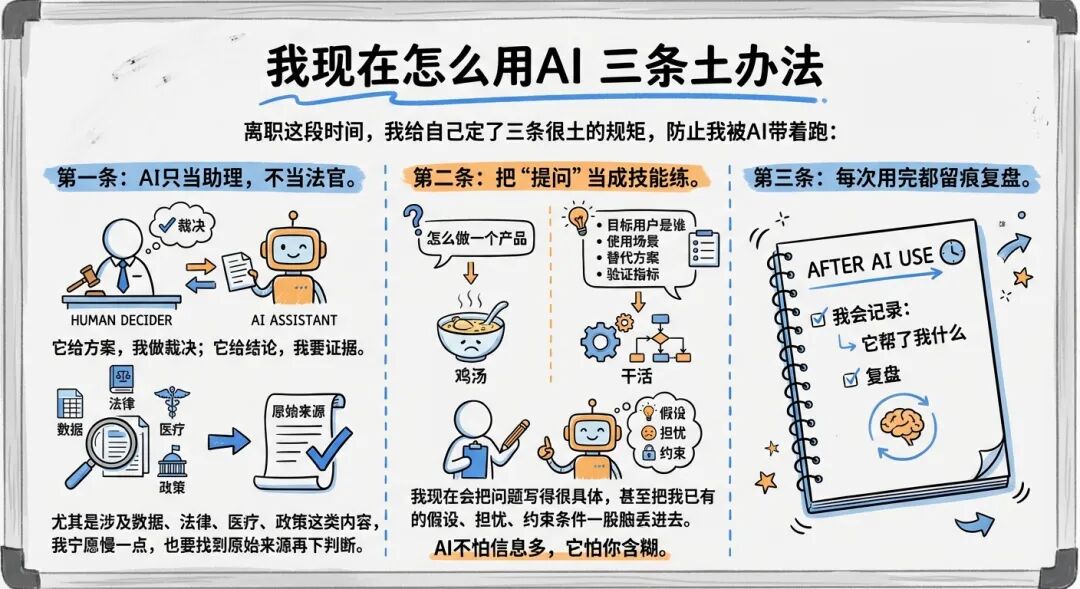
离职这段时间,我给自己定了三条很土的规矩,防止我被AI带着跑:
第一条:AI只当助理,不当法官。
它给方案,我做裁决;它给结论,我要证据。尤其是涉及数据、法律、医疗、政策这类内容,我宁愿慢一点,也要找到原始来源再下判断。
第二条:把“提问”当成技能练。
同一个问题,你问“怎么做一个产品”,它会给你鸡汤;你问“目标用户是谁、使用场景、替代方案、验证指标”,它才会开始干活。
我现在会把问题写得很具体,甚至把我已有的假设、担忧、约束条件一股脑丢进去。AI不怕信息多,它怕你含糊。
第三条:每次用完都留痕复盘。
我会记录:它帮了我什么、哪里胡说了、我怎么验证的、最后我怎么改的。这个习惯一开始很烦,但它能把“爽感”变成“能力”。不然你用一年AI,可能只是更熟练地依赖它。
顺便说个挺打脸的数据:很多人觉得AI会改善公共服务体验,但现实没那么快。
“仅有4%的受访者认为AI显著改善了其获得公共/政府服务的体验。” — Harvard Kennedy School(增长政策项目相关研究讨论)[https://www.hks.harvard.edu/centers/mrcbg/programs/growthpolicy/ai-needs-clinical-trials-harvards-findings-democratization]
这也提醒我:AI在个人层面很猛,在系统层面没那么灵。别急着神化,它还在落地路上。
离职后我对AI的最大改观,是从“工具很强”变成“门槛真的在松”。学习不再非得拜师,做产品不再非得组队,信息不再非得混圈子才能摸到。
但门槛松了,不等于世界就公平了。你省下的时间,要拿去做更难的事:判断、验证、取舍、承担后果。
我挺好奇:你最近用AI最爽的一次是什么?也欢迎说说你踩过的坑。评论区见,我想抄点真实案例当教材。
来源列表
-https://www.nu.edu/blog/ai-statistics-trends/ - https://internationalaisafetyreport.org/publication/international-ai-safety-report-2026 - https://techpolicy.press/expert-predictions-on-whats-at-stake-in-ai-policy-in-2026